AI 编程进阶指南
序言#
AI 编程正在逐步成为一种新的编程范式,非严格来区分包含 Vibe Coding 和辅助编程两种场景。在快速入门 AI 编程之后,如何最大限度发挥 AI 编程的优势,避免 Vibe Coding 遇到的各种棘手问题;程序员如何借助 AI 的加成,在未来的时代仍具有竞争力;...
AI 编程似乎正在成为一个新时代的潘多拉盒子,有人声称通过 Vibe Coding 开发应用变成赛道第一,也有的人觉得 AI 生成的代码完全不符合预期;有人通过 AI 能生成高质量的代码,也有人继续在屎山雕屎;...
中国人讲究「中庸」,过分地夸大 AI 编程的能力,以及过分贬低都是不可取的心态。面对 AI 编程,我们应该持有下面的心态:
- 积极,开放的心态拥抱 AI 编程:早尝试多尝试,与 AI 编程/工具一起成长。「新事物」的价值是巨大的,只有深入其中,才能撬动其巨大的杠杆效应,给自己带来巨大的效率提升。
- 大量学习,大量实践:目前 AI 编程正处在一个快速发展的阶段,无论是底层的模型的能力,抑或是上层工具,都在持续地动荡地发生变化。当前摸索出来的最佳实践, 或许过不了多久就已经被内置到工具中,或者不再有效了。另外,AI 编程是一个存在不确定的领域,不同习惯的细微差别,可能最终会存在巨大的影响。例如有一个建议是不要让AI改动太多的代码,它可能会把代码搞乱。那么,如何控制让AI不要改动太多的代码?改动多少代码算多?会改多乱?改乱了怎么办?…… 这里有太多细碎的问题,无法准确地用语言来说明,只能依赖大量的实践才会有真实的感受,也才能和AI建立恰当的信任关系。
- 不要放弃对代码的主导权:AI 编程虽然很强大,但如何拆解需求、如何设计系统、如何保证项目的可扩展性和项目质量等问题,依然需要人投入大量的心力来思考。如果放弃对于代码的主导权,将本来属于开发者的责任下放给 AI 编程,会导致项目的非常不可控。不放弃对代码的主导权,本质上就是不放弃解决问题的主导权。
- 提升综合能力:尽管未来AI编程会取代很多 "码代码" 的工作,而工程师的业务沟通与规划、问题拆解、领域建模、结果验证等工作,会逐渐变得更加重要。更进一步,如何突破现有的角色,将能力往上下游进行扩展。所以开发者如何在AI加持的时代,想清楚要学什么技能、训练什么能力,在这个时代都将变得更加重要。
- 提高对自己工作产出的要求:其实不论是否有AI编程,我们对于工作的标准应该都很高。但之前的问题是,如果编码工作占据了一个开发者的绝大多数时间,那很多提高标准的事情(例如用更多的时间做设计、更频繁地对系统进行重构、更多对系统进行测试等)都会因为时间的缘故而不得不降低标准。未来AI编程可以在很大程度上解放一个开发者的时间,那投入更多的思考来做一些提高标准的事情,就应该成为自我和团队的新的要求。
先计划,再执行#
当我们给大模型下达指令后,如果它立即开始编码,可能会有几个问题:
- 我们不知道自己的指令是否有清晰地传递给大模型,这里面可能是我们表达的遗漏,也可能是大模型的理解存在分歧
- 我们不知道大模型打算怎么执行,如果一个问题如果有多个解法的话,是否会选择我们更倾向的那一种
一个更好的做好做法是:对于复杂的任务,可以要求 LLMs 输出它对问题的理解,输出它的执行计划,待确认没问题之后,再由大模型来执行。
在 Cursor 中,有好几种方式来达到这一目的:
- 选择带推理的模型,比如 Gemini 2.5 thinking 模式、Claude-3.7-sonnet thinking 模式
- 在一个对话中,混用 Ask 和 Agent 模式,用 Ask 来制定计划,切换到 Agent 来进行代码实现
产出更多更优质的文档#
我们写文档的目的是为了帮助和沉淀思考,为了跟同事、跟未来的自己进行交流,在AI编程的时代,写出优质的文档相比之前有了更重要的意义:
- 在AI编程的时代,大家会有更多的时间来进行思考,也需要大家有更高质量的思考,而认真写文档可以帮助大幅提升一个人的思考质量。
- 在AI编程的加持下,一个人可以做更多的事情,负责更多的项目,而更清晰的文档可以方便一个人快速进入到新的上下文中开始工作。
- 在AI编程的上下文中,文档可以提供更加高密度的有效信息,提高AI 编程的质量。
考虑到:1)我们可以利用AI来帮我们写文档、完善文档;2)代码中的注释、项目的一些 README 文件也是AI编程中上下文的重要输入。因此我们如何将注释和项目文档组织在代码和项目中,如何利用AI去创建文档,如何利用AI去更新文档,如何在AI编程的过程中引入文档,都值得进一步讨论。 一些实践是:
- 所有的代码注释和文档,不论是否由AI生成,必须认真审核和整理,达到我自己写作的质量。对于文档是否清晰准确的重视程度甚至要超过代码。这里的逻辑是,我觉得文档不仅是人与人交流的工具,也将越来越多扮演人和AI交流的角色。
- 在有代码更新的时候,自己或依赖AI来更新文档的描述,保证文档的描述和代码的逻辑是一致的。
- 逐渐形成一些自己写文档的惯例,例如在每一个包下可以有一个文档来说明跟这个包相关的信息,例如在每一个文件的最上面会有文档描述整个文件对外暴露的接口等。
最后需要说明:文档应该是衡量一个开发者,甚至是一个职场人综合能力的重要参考。很难给出一套标准,来说明什么样的文档是好的,什么样的文档是不好的。但不论如何,追求更高的文档质量,是AI编程时代对于每一个开发者的基本要求。
主动管理会话上下文#
现在几乎所有的 AI 编程工具,全都以“代码编辑 + 对话”的形态提供。理想的状态下,我们应该只关心对话窗口,在对话窗口中不断提出自己的需求,AI 则按照我们的要求进行代码实现。理想状态下,AI 应该表现得像一个“智人”,对我们的项目代码有通篇地了解。但很遗憾,AI 目前还达不到这个水平。
为了实现更好的效果,我们都应该主动介入上下文的管理。管理上下文的最终目标应该是:不多不少,跟当前的解决的问题高度相关。实际上要做到这个程度也不太容易,在实践中,反而是尽可能多给,而不是少给。
主动管理上下文是当前提升 AI 编程效率/效果的非常重要的手段。以 Cursor 为例,很多的功能设计都是围绕上下文管理展开的。同时,管理上下文也是有一些技巧的。
- 技巧一:主动引入相关上下文
目前虽然 Cursor 等工具提供了自动索引依赖的代码文件和内容(通过 codebase_search 或 Code Indexing),但本身是依赖 LLMs。如果 LLMs 在理解上出现偏差,效果会大打折扣。主动引入上下文,理论是可以达到更好的效果。
在 Cursor 中,@ 可以引用多种类型的上下文。一个示例可以是:
参考 @a.ts 的代码实现,在 @b.ts 为我实现 xxx 功能
- 技巧二:一个对话窗口不要做太多的事情,为新问题启用一个新的对话
不要试图在一个对话中完成所有的事情,不相关的上下文会让 AI 无法专注,造成信息干扰。一个对话窗口应该是只包含高度相关的内容,可以是实现一个底层函数,也可以是为了某个功能而实现的多个函数。换句话说,两个对话窗口实现的功能应该是相对独立的。
一个有效的开发工作流大概是:
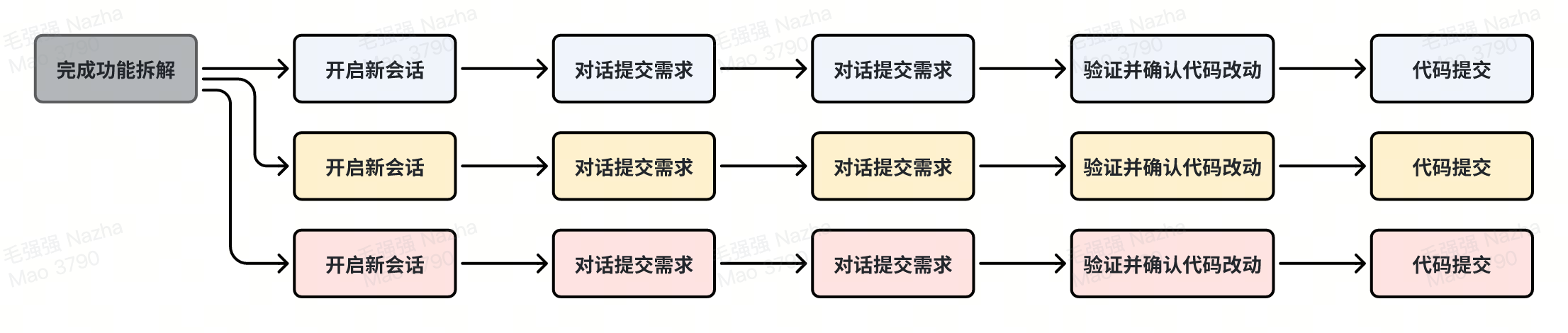
在 Cursor 中,我们还可以通过 @Past Chats 功能来引入之前的对话内容。
提出自己的解法#
AI 不是万能的,当它出错或者我们心中已有正确的解答时,把我们的想法告诉它,引导 AI 往我们想要的方向走。一个很好的策略是提供伪代码或框架代码,让 AI 去实现具体细节。
限制 AI 修改的文件范围#
这里不讨论 Vibe Coding 的场景,只讨论严肃编码的场景。我们应该有意控制 Coding Agent 修改代码的范围,在它完成改动之后,对代码进行验证,如果没问题再继续。
当然,不限制 Coding Agent 的修改范围有时候更能获得意想不到的效果,但多数情况下,是「负」效果。
一个示例可能是:
实现 xxx 功能,但修改只涉及 @a.ts、@b.ts 和 @a.css 这三个文件
测试用例优先#
测试驱动开发(TDD)的策略在 AI 编程阶段显得尤为重要。在传统的开发流程中,虽然我们都明白 TDD 的重要性,但全量测试用例的编写会占用大量的开发时间,更缺乏精力和动力来维护测试用例。
一方面,我们可以借助 AI 来编码高质量的测试用例;另一方面,高质量的测试用例会同时让项目和 AI 受益:
- AI 编程会大幅加快项目开发节奏,如何在快节奏下保持代码质量,测试覆盖是一种重要的手段
- AI 编程会让完成测试用例的成本急剧下降,同时也会降低测试用例编写的门槛
- 更重要的是,完备的测试用例也是 Coding Agent 的重要反馈,根据测试的执行情况,Agent 可以不断调整自己的代码。在实践中,可以要求 Agent 对代码完成改动之后,必须执行现有的测试用例,来提高其代码的可靠性。
提交前对代码进行优化#
在所有功能开发完成,测试用例覆盖完备的情况下,再调用大模型进行几轮代码优化,目的是让代码结构更清晰,代码实现更优雅,代码可读性更好。
如果现在的我都看不懂 AI 写的代码,那么未来的我和同事也很难理解这套代码。当然,理想情况下是,无论是现在还是未来,都由 AI 来接手这段代码,但目前来说,会给项目带来风险。
当然,即使不做这件事,也没有什么问题,同时还要面临代码重构带来的风险。最优的解法,我们应该保证大量的测试用例覆盖。
执行层面,可以维护一个“代码优化指南.md” 的文档,在每次进行代码优化时,采用类似下面的提示词:
参考 @代码优化指南.md 中的建议,对 @file 进行优化
学习如何写好提示词#
一直依赖,随着模型能力的增强,不需要提示词工程的言论甚嚣尘上。在实践中,我们发现好的提示词仍然能大幅提高模型的输出。写好提示词,仍然非常重要。
写提示词有很多框架(比如 RTGO 和 CO-STAR),本质上是提供足够的上下文,表述清楚我们的需求,且不容易产生二义性。系统学习提示词工程,有一些好的资源,比如 Anthropic 和 [Google Prompt Engineering](https://www.kaggle.com/whitepaper-prompt-engineering 这两个教程。
想要表达清楚的前提是想清楚,但想清楚了不一定能表达清楚。另一个关键,是我们需要刻意地大量训练,迭代我们写提示词的能力。有时候,不能为了快,而忽略掉提示词的建设。
在写提示词的过程中,应该尽量侧重结果,而非过程。具体的实现过程可交给 Thinking 步骤进行规划。